MotionFix: Text-Driven 3D
Human Motion Editing
SIGGRAPH Asia 2024

Video
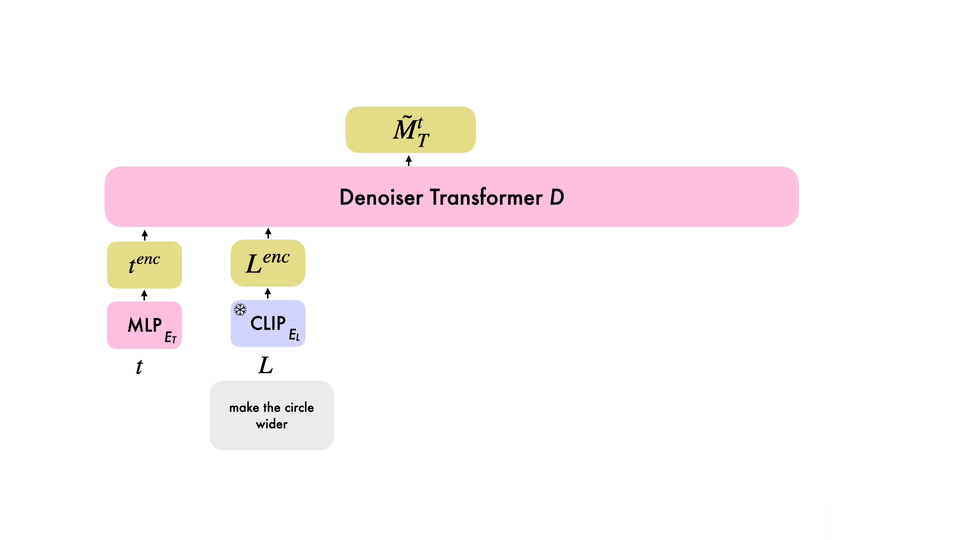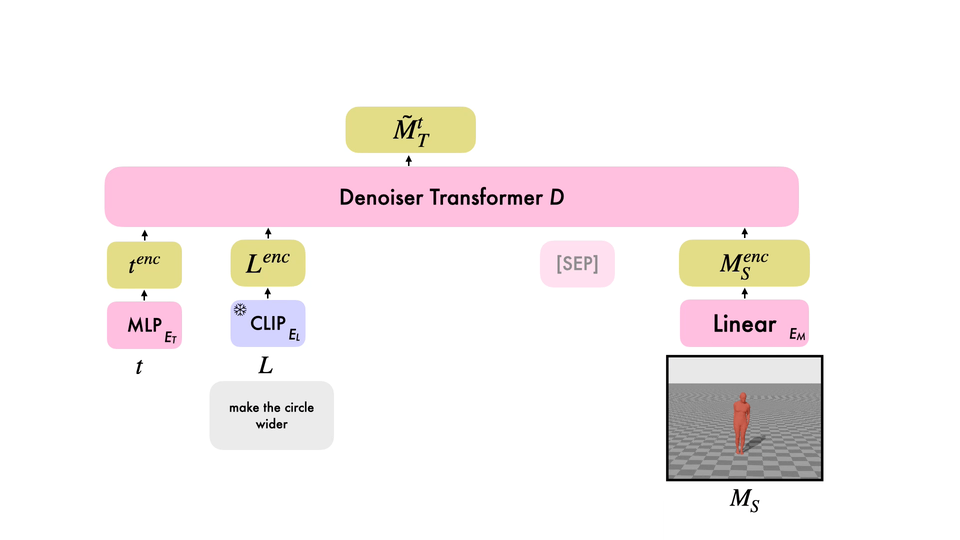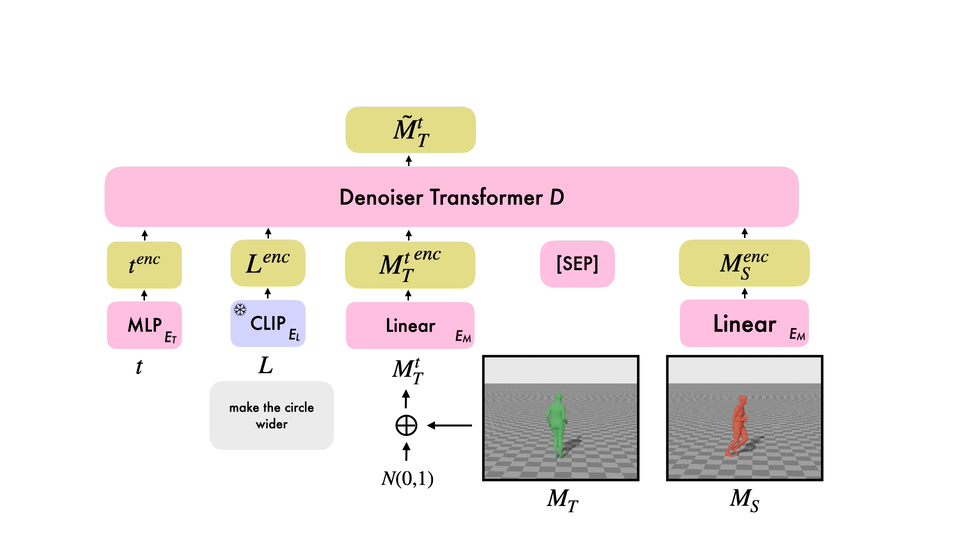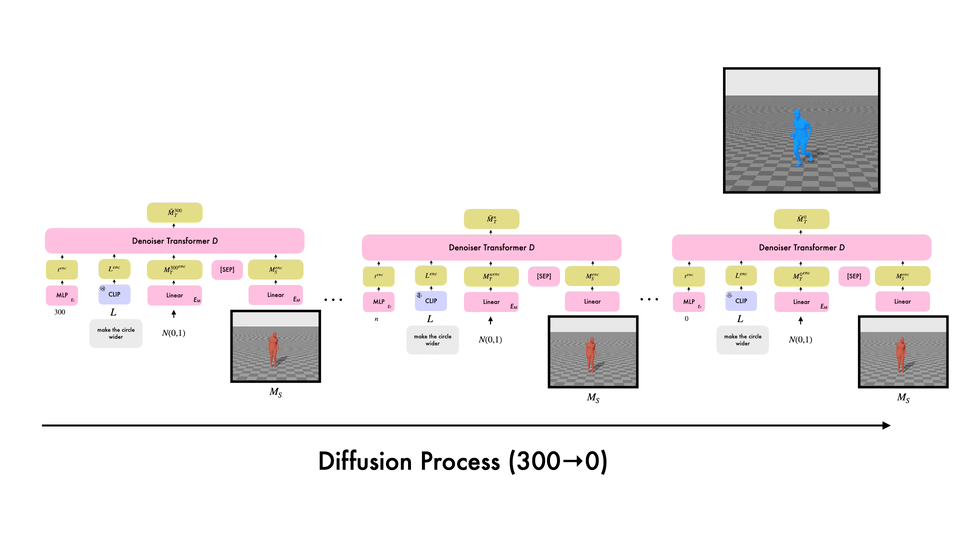
Editing Different Motions

Acknowledgements
We are grateful to Tsvetelina Alexiadis for valuable data collection guidance and managementof both the studies and the data collection process.
We are also grateful to Arina Kuznetcova, Asuka Bertler, Claudia Gallatz, Suraj Bhor, Tithi Rakshit for data annotation, Taylor McConnell, Tomasz Niewiadomski for data annotation and help with design of the annotation interface.
Their help was extremely significant for collecting the data and completing the project.
The authors would like to thank Benjamin Pellkofer for IT support and the development of the data exploration webpage. His help was essential for making this dataset easily accesible to the users.
We also thank Lea Müller for initial discussions about diffusion models and Mathis Petrovich for discussions about human motion representations and diffusion details. The first author is also thankful to Peter Kulits for his support and seatmating. The first author would also like to thank the members of Imagine Lab for hosting him and providing a welcoming research environmnent.
Finally, we thanks Yuliang Xiu for proofreading.
BibTex
@inproceedings{athanasiou2024motionfix,
title = {{MotionFix}: Text-Driven 3D Human Motion Editing},
author = {Athanasiou, Nikos and Ceske, Alp{\'a}r and Diomataris, Markos and Black, Michael J. and Varol, G{\"u}l},
booktitle = {SIGGRAPH Asia 2024 Conference Papers},
year = {2024}
}